The rapid evolution of AI agents has created a key challenge: how to build and deploy agents quickly and efficiently. Imagine creating intelligent agents that can not only perform complex tasks but also interact easily with your data infrastructure, without adding unnecessary complexity to the code.
This guide introduces AgentStack, a rapid development framework, and Neon, the serverless Postgres database, and shows how they can be used together to build powerful AI agents with database integration. We'll walk through building a Web Scraper AI Agent using AgentStack's CLI and tool integrations.
With AgentStack and Neon, you can generate complete agent workflows, create new agents and tasks with simple commands, and integrate them directly with your data layer. Let's get started.
What you will build
This example will show you how to:
- Set up an AgentStack project.
- Use the AgentStack CLI to generate agents and tasks.
- Equip your agents with tools like Neon for data storage and Firecrawl for web scraping.
- Run your agent crew to scrape the neon.tech/guides page, extract blog post metadata (titles, authors, dates) from it, and store it in a Neon Postgres database.
- Use AgentOps for observability of your agent's execution.
Prerequisites
Before you start building your Web Scraper Agent, ensure you have the following prerequisites in place:
- Python 3.10 or higher: Download from python.org.
- uv package installer (or Poetry): Recommended for faster dependency installation. Install
uvas described here: astral-sh/uv. Alternatively, usepoetry. - AgentStack CLI: Install the AgentStack Command Line Interface (CLI). Follow the Getting started with AgentStack guide.
- Accounts and API Keys: You will need accounts and API keys for these services:
- OpenAI API key: We will use OpenAI's
gpt-4o-minimodel to power AI agents. Get an OpenAI API key at platform.openai.com. - Neon account: Sign up for a free Neon account at neon.tech. You will need a Neon API key to connect to your Neon database.
- Firecrawl account: Sign up for a Firecrawl account at firecrawl.dev. You will need a Firecrawl API key to use the web scraping tool.
- AgentOps account: Sign up for an AgentOps account at agentops.ai to leverage agent observability features. You will need an AgentOps API key.
- OpenAI API key: We will use OpenAI's
Building the Web Scraper agent
Let's start building our agent using AgentStack, Neon, and Firecrawl. We'll walk through each step, from initializing the project to running the agent crew.
Project setup with AgentStack CLI
AgentStack simplifies project setup with its CLI. Let's start by initializing a new AgentStack project.
-
Initialize AgentStack Project:
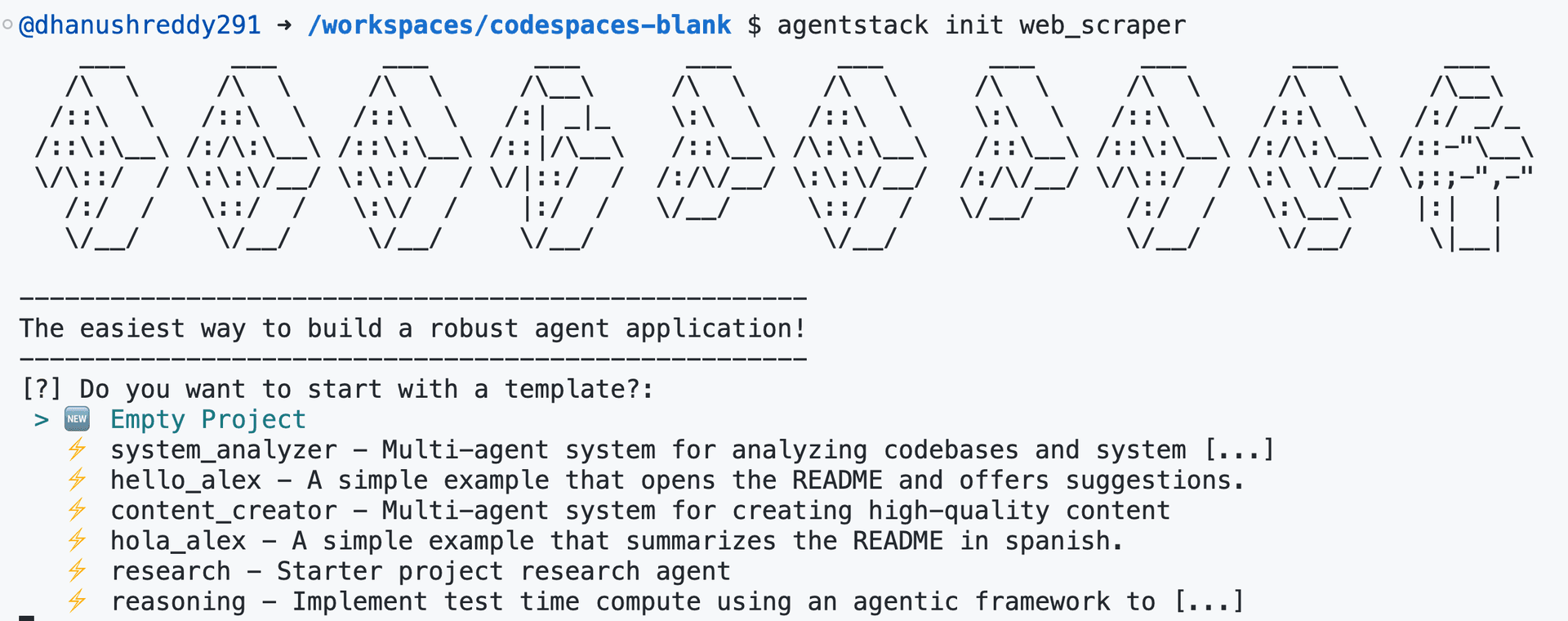
Open your terminal and run the following command to initialize a new AgentStack project named
web_scraper:agentstack init web_scraperAgentStack CLI will prompt you to select a template. Choose the Empty Project template for this guide.
-
Navigate to your project directory and activate the virtual environment:
cd web_scraper && source .venv/bin/activate
Project structure
After initialization, your project directory web_scraper will have the following structure:
web_scraper/
├── agentstack.json # AgentStack project configuration
├── pyproject.toml # Python dependencies
├── .env # environment variables file
├── src/
│ ├── crew.py # Defines your agent crew and workflow
│ ├── main.py # Main script to run your agent
│ ├── config/ # Configuration files
│ ├── agents.yaml # Agent configurations
│ └── tasks.yaml # Task configurationsGenerating agents with AgentStack CLI
We will create 3 agents for our Web Scraper crew:
web_scraper: Responsible for web scraping and markdown extraction.data_extractor: Specialized in extracting structured data from web content.content_storer: Manages storing extracted data in a Neon Postgres database.
Now, let's generate the agents using the AgentStack CLI.
-
Generate
web_scraperagent:agentstack generate agent web_scraperWhen creating the first agent,
agentstackwill ask you to choose a default Large Language Model (LLM). We recommendopenai/gpt-4o-minifor this guide, as it offers a good balance between performance and cost. You will need to enter this model name manually, as it's not included in the default list.
-
Generate
data_extractoragent:agentstack generate agent data_extractor -
Generate
content_storeragent:agentstack generate agent content_storerAgentStack CLI uses simple commands to generate the basic structure for your agents and tasks, significantly speeding up the development process.
Configuring agents in agents.yaml
Open src/config/agents.yaml and configure the agents as follows:
web_scraper:
role: >-
Web scraper specializing in markdown extraction.
goal: >-
Visit a website and accurately return its content in markdown format.
backstory: >-
You are a meticulous data entry employee with expertise in web scraping and markdown formatting. Your task is to retrieve website content and present it clearly in markdown.
llm: openai/gpt-4o-mini
data_extractor:
role: >-
Data extraction expert for web content analysis.
goal: >-
Analyze web page content and extract structured information
backstory: >-
You are an expert data analyst skilled in extracting key information from web pages. You are adept at identifying and listing key details such as blog post titles, author names, and publication dates from website content.
llm: openai/gpt-4o-mini
content_storer:
role: >-
Database engineer
goal: >-
Store structured web content in a Postgres database, create relevant tables, insert data, and formulate SQL queries to retrieve stored data.
backstory: >-
You are an expert database engineer. You are skilled in database design, data insertion, and writing efficient SQL queries for data retrieval.
llm: openai/gpt-4o-miniAgentStack uses YAML configuration files to define the roles, goals, and backstories of our agents. This configuration-driven approach makes it easy to modify and extend our agent crew without changing code.
Generating tasks with AgentStack CLI
Now that we have our agents defined, we need to create tasks for them. Tasks define the specific actions each agent will perform within the agent crew's workflow.
For this example the task for the AI agent is simple: get the list of blog post titles, author names, and publication dates from our guides page and store it in a Postgres database.
We will need three tasks for our Web Scraper crew:
-
Generate
scrape_sitetask:agentstack generate task scrape_site -
Generate
extracttask:agentstack generate task extract -
Generate
storetask:agentstack generate task store
Configuring tasks in tasks.yaml
Open src/config/tasks.yaml and configure the tasks as follows:
scrape_site:
description: >-
Fetch the content of https://neon.tech/guides in markdown format. Ensure accurate and complete retrieval of website content.
expected_output: >-
The complete content of the website https://neon.tech/guides, formatted in markdown.
agent: >-
web_scraper
extract:
description: >-
Analyze the provided website content and extract a structured list of blog post titles, author names, and publication dates. Limit the extraction to the first 20 blog posts.
expected_output: >-
A list of blog post titles, author names, and publication dates extracted from the website content.
agent: >-
data_extractor
store:
description: >-
Store the extracted blog post data into a Postgres database within Neon. Create a table named 'posts' and corresponding schema for the posts and insert them. After inserting the data, formulate and test an SQL query to retrieve all inserted data. Provide the tested SQL query as the output.
expected_output: >-
A valid and tested SQL query that retrieves all data inserted into the 'posts' table in the Neon database.
agent: >-
content_storerSimilar to agents, tasks are also configured via YAML, defining the description of the task, the expected output, and the agent assigned to perform it. This makes the workflow easily understandable and modifiable.
Adding Firecrawl and Neon tools to the Crew
To enable web scraping and data storage capabilities, we will integrate Firecrawl and Neon tools into our agent crew. We will use Firecrawl for web scraping the neon.tech/guides page and Neon for storing the extracted data in a Postgres database.
-
Add Firecrawl tool using the following command:
agentstack tools add firecrawl -
Add Neon tool using the following command:
agentstack tools add neon
The agentstack tools add command simplifies the integration of tools by automatically updating your project configuration and crew.py file to include the necessary tool classes.
Understanding Neon Tool actions
AgentStack's Neon tool integration equips the agents with a suite of pre-built actions to interact with Neon serverless Postgres databases. These actions are automatically available to any agent you equip with the Neon tool, like the content_storer agent in our example. The Neon tool provides the following actions:
-
create_database: This action allows our agent to create a new Neon project and database on demand. It returns a connection URI, which is essential for subsequent database interactions. By default, it creates a database namedneondbwith the roleneondb_owner. This is particularly useful for agents that need to manage their own isolated databases or when the database needs to be created as part of the agent workflow. -
execute_sql_ddl: Agents use this action to execute Data Definition Language (DDL) commands. DDL commands are used to define the database schema, such as creating, altering, or dropping tables. For instance, thecontent_storeragent uses this action to create thepoststable in the Neon database. -
run_sql_query: This action enables agents to run Data Manipulation Language (DML) queries likeSELECT,INSERT,UPDATE, andDELETE. In the example, thecontent_storeragent uses this action to insert the scraped blog post metadata into thepoststable and to formulate and test aSELECTquery to retrieve the data. The results from these queries are returned to the agent as formatted strings, allowing the agent to process and reason about the data.
These actions empower our agents to fully manage and utilize Neon databases within their workflows, from database creation and schema definition to data manipulation and retrieval, all without requiring manual coding of database interactions.
Understanding Firecrawl Tool actions
AgentStack's Firecrawl tool integration provides the agents with a set of actions to perform web scraping tasks. These actions are readily available to any agent equipped with the Firecrawl tool, like the web_scraper agent in our example. The Firecrawl tool offers the following actions:
-
web_scrape: This action allows our agent to scrape the content of a single webpage and retrieve it in markdown format. It's designed for efficiently extracting content from individual URLs when we need the content of a specific page. The agent provides a URL, and Firecrawl returns the webpage's content as markdown text. -
web_crawl: For more extensive data gathering, theweb_crawlaction enables our agent to initiate a web crawl starting from a given URL. This action not only scrapes the initial URL but also explores and scrapes content from linked pages that are children of the starting URL. It's important to note that the crawl is limited to sublinks of the provided URL, preventing it from venturing to entirely separate sections of a website or different domains. This action is asynchronous and returns acrawl_id. -
retrieve_web_crawl: Sinceweb_crawlis an asynchronous operation, we use theretrieve_web_crawlaction to get the results of a crawl that was initiated previously using theweb_crawlaction. This action requires thecrawl_idthat was returned by the initialweb_crawlaction. It checks the status of the crawl and returns the scraped content once the crawl is complete. Agents can use this action in a loop or after a delay to check for and retrieve crawl results, allowing for more complex workflows where web crawling is part of a longer process.
These actions equip our agents with powerful web scraping capabilities, ranging from simple single-page content extraction to comprehensive crawling of website sections, enabling them to gather web data effectively as part of their tasks.
We can improve the efficiency of our agents by specifying their tool usage in crew.py. Since the web_scraper agent only needs firecrawl, the content_storer agent only needs neon, and the data_extractor agent needs no tool, assigning these tools directly in the configuration will reduce agent context memory and enable more focused task execution, mirroring human specialization.
Your src/crew.py file should now look like this, with the tools integrated into the respective agents:
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
import agentstack
@CrewBase
class WebscraperCrew:
"""web_scraper crew"""
@agent
def web_scraper(self) -> Agent:
return Agent(
config=self.agents_config["web_scraper"],
tools=[*agentstack.tools["firecrawl"]],
verbose=True,
)
@agent
def data_extractor(self) -> Agent:
return Agent(
config=self.agents_config["data_extractor"],
tools=[],
verbose=True,
)
@agent
def content_storer(self) -> Agent:
return Agent(
config=self.agents_config["content_storer"],
tools=[*agentstack.tools["neon"]],
verbose=True,
)
@task
def scrape_site(self) -> Task:
return Task(
config=self.tasks_config["scrape_site"],
)
@task
def extract(self) -> Task:
return Task(
config=self.tasks_config["extract"],
)
@task
def store(self) -> Task:
return Task(
config=self.tasks_config["store"],
)
@crew
def crew(self) -> Crew:
"""Creates the Test crew"""
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)Configure API keys in .env
To authenticate with OpenAI, Neon, and Firecrawl, you need to configure API keys. Open the .env file and fill in your API keys obtained in the Prerequisites section:
OPENAI_API_KEY=YOUR_OPENAI_API_KEY
NEON_API_KEY=YOUR_NEON_API_KEY
FIRECRAWL_API_KEY=YOUR_FIRECRAWL_API_KEY
AGENTOPS_API_KEY=YOUR_AGENTOPS_API_KEYRunning the Web Scraper agent
Now that we have set up our agents, tasks, and tools, let's run the agent crew to scrape the neon.tech/guides page, extract blog post metadata, and store it in a Neon Postgres database.
agentstack runThis command will:
- Initialize the AgentStack environment.
- Load agent and task configurations.
- Instantiate the agent crew defined in
src/crew.py. - Execute the tasks in sequence.
- Utilize the
neonandfirecrawltools within the agents' tasks as defined insrc/crew.py. - Print the final output to your terminal.
You should see the agent's execution logs and the final output, including the final SQL query generated by the content_storer agent.
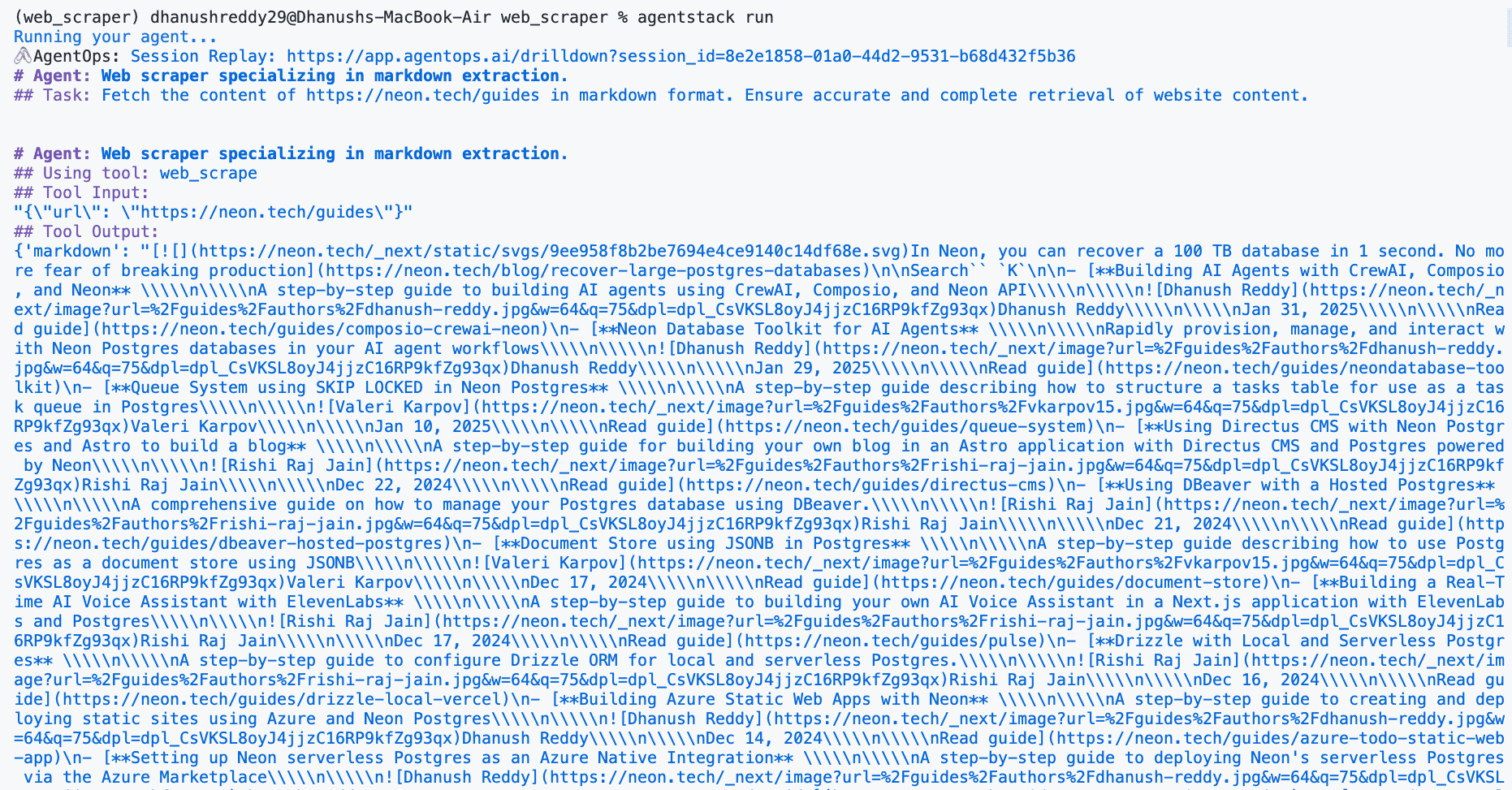

Verifying the output
After the agent run completes, check your terminal for the output. It should display the SQL query generated by the content_storer agent.
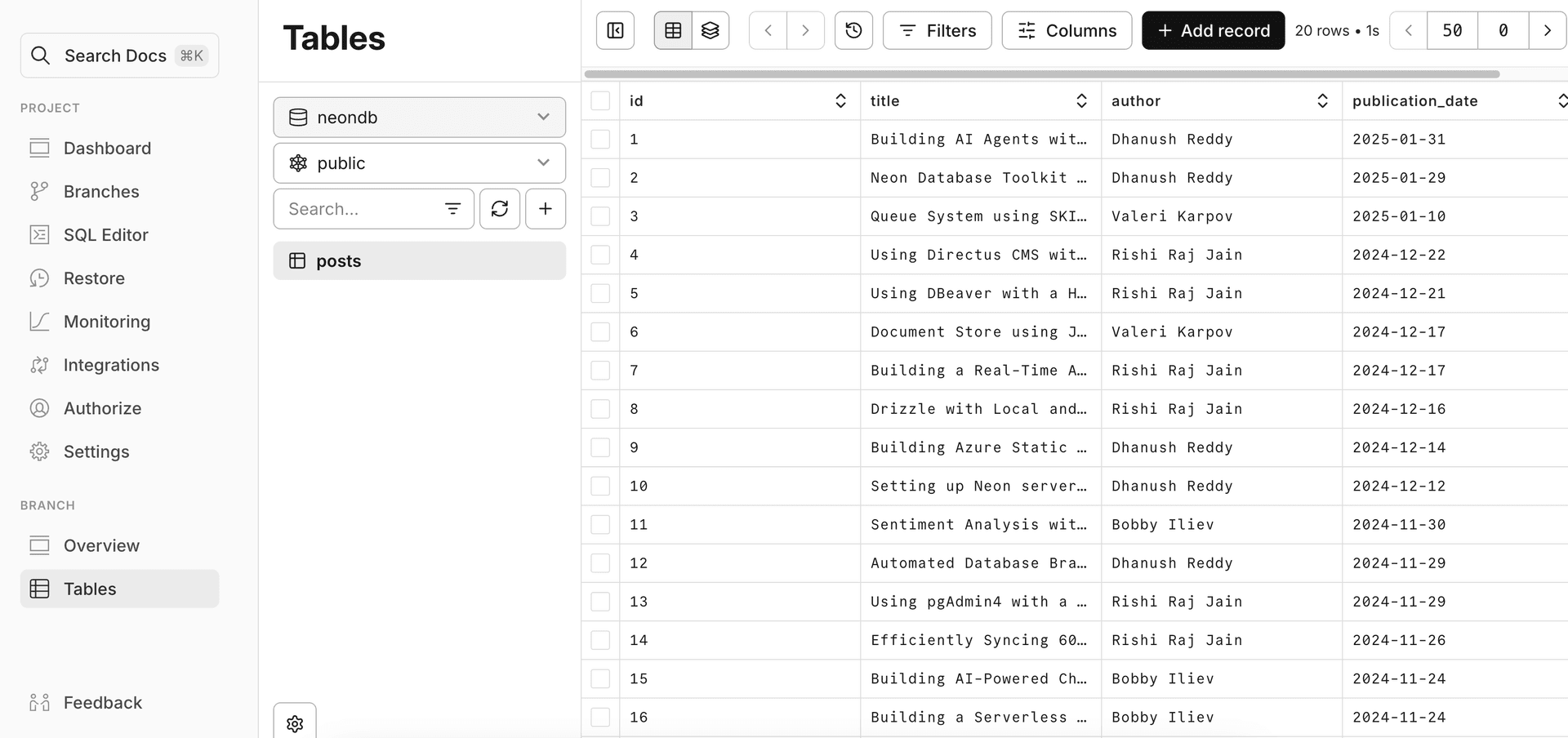
You can verify that the data has been stored in your Neon database by:
- Logging into your Neon account at console.neon.tech.
- Navigating to your project and database.
- Clicking on the
Tablestab to view thepoststable created by the agent.
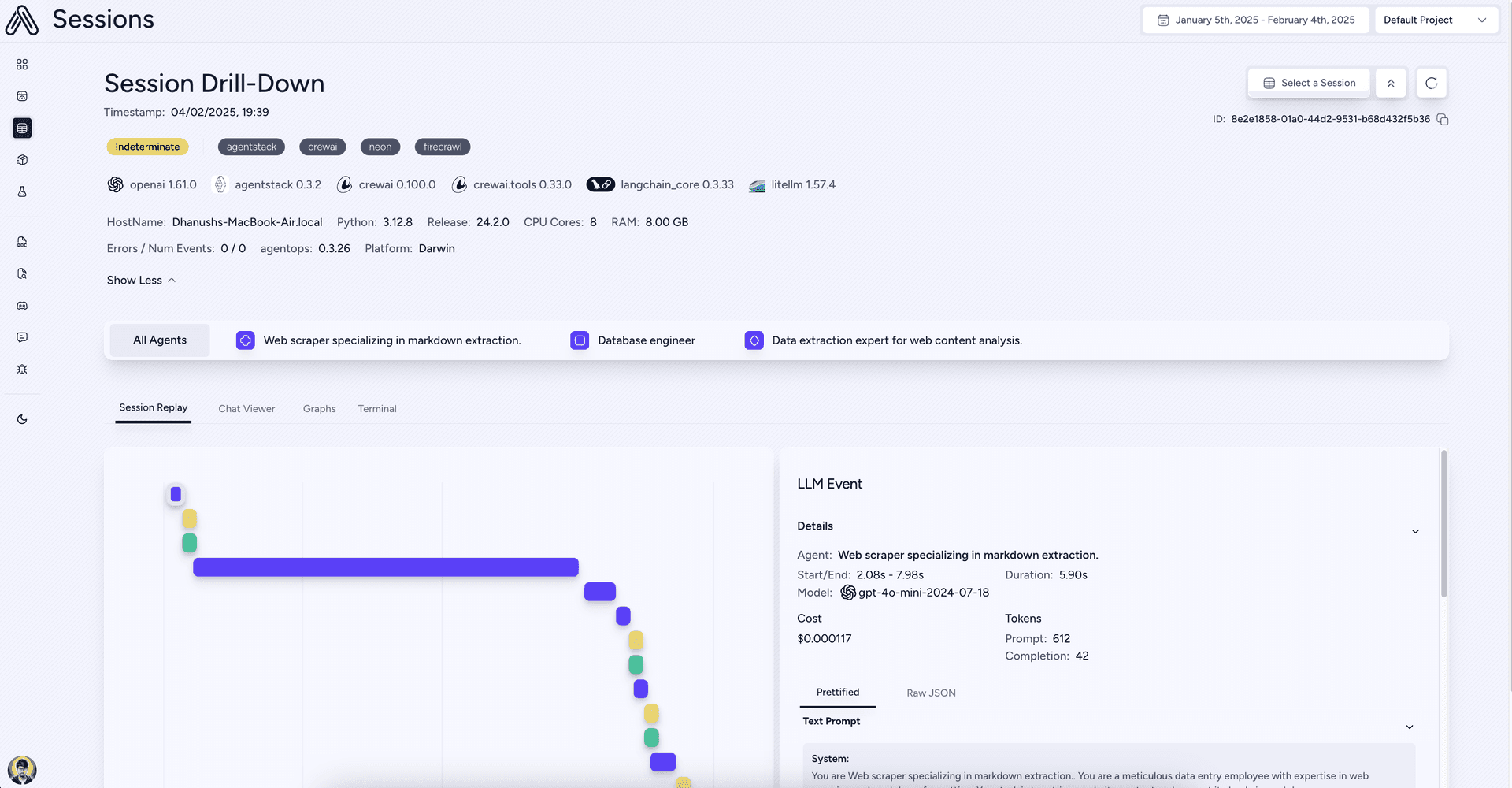
AgentOps: Gain Observability into your AI Agents
AgentStack integrates with AgentOps by default to provide full observability for your AI agent development. Built by the same team behind AgentStack, AgentOps allows you to:
- Visualize agent execution: See step-by-step execution graphs of your agents, making it easy to understand workflows and debug issues.
- Track LLM costs: Monitor your spending on LLM providers to manage costs effectively.
- Benchmark Agent performance: Evaluate agent performance and ensure quality.
- Enhance security: Detect potential vulnerabilities like prompt injection.
To use AgentOps, make sure you have your AGENTOPS_API_KEY configured in your .env file (as covered in the Prerequisites). AgentOps automatically starts tracking your agent executions when you run agentstack run because of the agentops.init() call in src/main.py.
Use AgentOps to gain insights into your agents' behavior and performance, allowing for continuous improvement and optimization.
With a total run cost of only $0.01 in OpenAI credits (as seen in the AgentOps dashboard), this AI agent runs efficiently while requiring no custom code. It avoids complex programming for tasks like web-scraping and SQL queries, making it widely applicable.
Congratulations! You have successfully built and run a Web Scraper agent using AgentStack, Neon, and Firecrawl, demonstrating how to automate web data extraction and storage into a serverless Postgres database with minimal effort!
Next Steps
- Explore more tools: Browse AgentStack's community tools, including Perplexity (knowledge retrieval), Composio (platform connections), and Stripe (payments).
- Expand your crew: Add more agents and tasks to handle complex workflows.
- Monitor performance: Use AgentOps to track and optimize execution and costs.
You can find the source code for the application described in this guide on GitHub.
Resources
- AgentStack Documentation
- AgentOps Documentation
- Firecrawl Documentation
- Firecrawl AgentStack Tool
- CrewAI Documentation
- Neon AgentStack Tool
- Neon API Reference
- Neon API keys
Need help?
Join our Discord Server to ask questions or see what others are doing with Neon. Users on paid plans can open a support ticket from the console. For more details, see Getting Support.